|
Datasets |
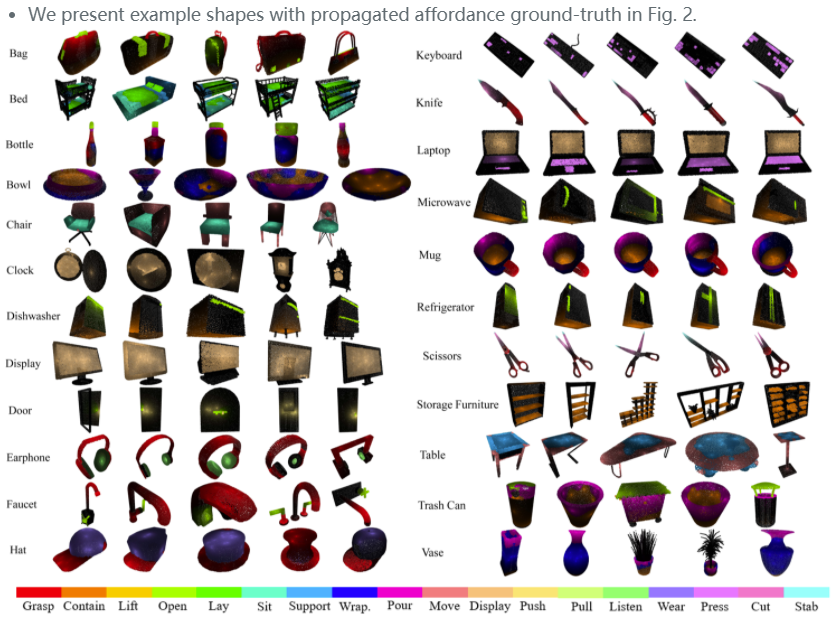 |
3D AffordanceNet is the first 3D dataset for study of visual object accordance learning. It consists of 23K object shapes annotated with 18 visual affordance categories, and supports full- or partil-view affordance estimations in different learning setups. For usage of the dataset, please refer to our Github page. |
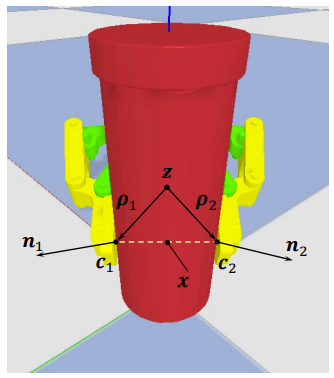 |
We contribute a synthetic dataset of 6-DOF object grasps, including 22.6M annotated grasps for 226 object models. It is constructed using physics engine of PyBullet. For usage of the dataset, please refer to our Github page. |
 |
The dataset contains pre-computed skeletal point sets and skeletal volumes for object instances in the ShapeNet dataset. The data are prepared for our CVPR19 paper A Skeleton-Bridged Deep Learning Approach for Generating Meshes of Complex Topologies From Single RGB Images. For usage of the dataset, please refer to our Github page. |
 |
The dataset is prepared for our paper ROML: A Robust Feature Correspondence Approach for Matching Objects in A Set of Images published in IJCV. The dataset contains 6 image sets of different object categories: Airplane, Face, Motorbike, Car, Bus, and (the logo of) Bank of America. The original images are from Caltech101 and MSRC datasets. Play fun! |