|
Grasp Proposal Networks: 一种端到端全自由度抓取姿态估计网络简介
|
机器人抓取物体是机器人模仿人类行为的一项基本功能。机器人从视觉观测中学习如何合理地抓取场景中的物体,是一项具有实际应用但又具有挑战性的任务。例如物品的分拣、家庭智能机器人与人的交互等场景中,都会涉及到机器人抓取任务。这个任务的挑战在于:1)视觉感知具有一定的不精确性和噪声,2)机器人在规划抓取路径和执行抓取时可能有一定的系统误差,3)单从视觉观测中,机器人无法获取被抓取物体的物理属性,例如物体的重心、材质、摩擦系数等等。
近期的一些工作[1], [2]表明了利用大规模的合成数据来训练深度学习模型,可以在真实场景中达到很好的鲁棒性和泛化能力,即使合成数据与真实数据有一定的域间差异。但现在的这些工作主要集中于解决基于四自由度(4-DOF)的平面抓取,即机器人的爪子是垂直于桌面从上往下抓取物体的,这大大限制了机器人抓取的灵活性。因此,本文提出了一个合成的六自由度(6-DOF)的数据集,同时提出了生成六自由度抓取的神经网络结构Grasp Proposal Network(GPNet)。我们的方法相对于现有的6-DOF抓取方案[3], [4],在抓取成功率和抓取多样性两个标准上都有很大的提升。
在考虑二指甲的抓取前提下,现有的机器人抓取方式主要有两种:基于四自由度的平面抓取和基于六自由度的抓取,如下图所示:
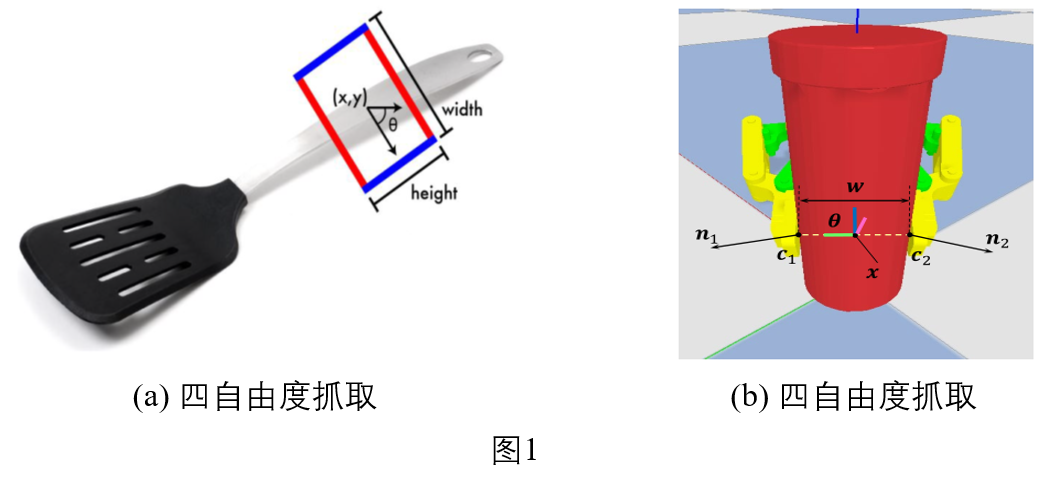
在四自由度抓取中,机器人的抓取方向被限制从上往下抓,其参数有四个:抓取中心点(x, y),抓取旋转角θ,爪子张开宽度w。有的研究人员为套检测的框架,一般会引入另外一个参数h,将抓取姿态表示成一个有朝向的长方形[5]。四自由度虽然参数少,比较容易学习,但很大的限制了机器人抓取的灵活性。而六自由度抓取则更加灵活,机器人可以从任意方向对物体进行抓取,只要抓取姿态满足机器人本身的运动学约束即可。六自由度抓取的参数表示为:抓取中心点$\textbf{x}=(x,y,z)$,三个欧拉角$\textbf{θ}\in[-π,π]^3$。有时也会考虑爪子张开的宽度w。
基于视觉观测获取机器人抓取姿态任务中,主要技术路径有两种:1)基于采样的方法;2)基于学习的生成方法。如下图所示:
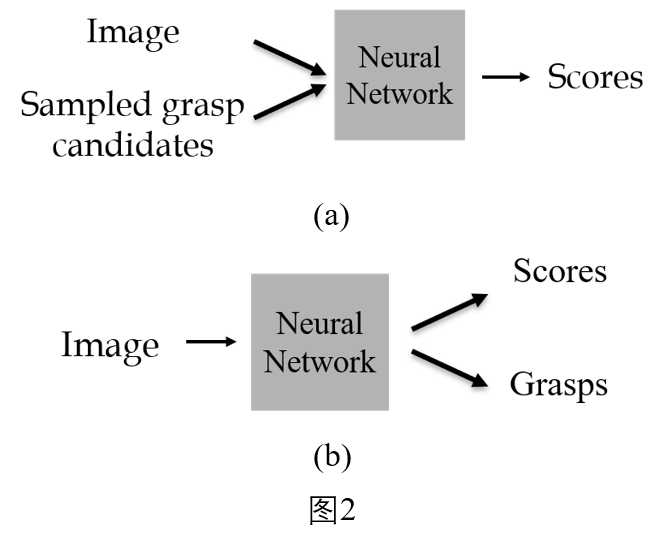
在基于采样的方法中,人们从观测的图像或点云数据中,根据物体的局部几何性质,采样一些候选的抓取姿态,再将这些采样的抓取姿态和观测数据一起,送到神经网络中进行打分,根据分数筛选出成功的抓取姿态[4], [6]。这种方法的缺点在于采样的抓取姿态数量非常有限,并且后续的抓取评分阶段需要的时间会随抓取数量的增加线性增长。在基于学习的方法中,直接用神经网络从观测的数据中估计抓取姿态和对应的分数[5]。这种方法可以很高效地从观测中得到大量的抓取姿态。但这种方法的缺点在于,网络估计的分数不能很好的反映对应的抓取的质量。[3]提出了用一个VAE网络从观测中采样抓取姿态,后面再接着一个训练好的抓取评估网络对采样的抓取姿态进行评分,但他们的方法并不能以端到端的方式进行训练,并且不能避免评估时间随抓取数量增加而线性增长的问题。
针对现有方法存在的问题,本文提出了一个端到端的抓取生成网络,以及一个在模拟环境里收集的六自由度抓取数据集。我们的方法在抓取成功率和抓取多样性等指标上,都比现有的方法有很大的提升。
本文只考虑基于平行二指甲的单物体六自由度抓取问题。我们假设物体摆放于一个世界坐标系中,一个基于平行爪的六自由度抓取姿态可参数化为$\textbf{g}=(\textbf{x},\textbf{θ})$,其中$\textbf{x}=(x,y,z)$表示平行爪抓取时的中心点,$\textbf{θ}\in[-π,π]^3$ 表示爪子旋转方向的三个欧拉角。此处,我们采用一种等价的抓取姿态参数化方式:$\textbf{g}=(\textbf{c}_1,\textbf{x},ϕ)$。其中,$\textbf{c}_1$是爪子抓取物体时与物体的两个接触点之一,$\textbf{x}$是抓取中心点,$ϕ$表示爪子绕着连接两接触点的轴线转动的俯仰角,为直观理解,可参考图1(b)。
在这种新的抓取参数化方式,我们很自然的提出了以下生成抓取姿态的网络框架,如下图3所示。
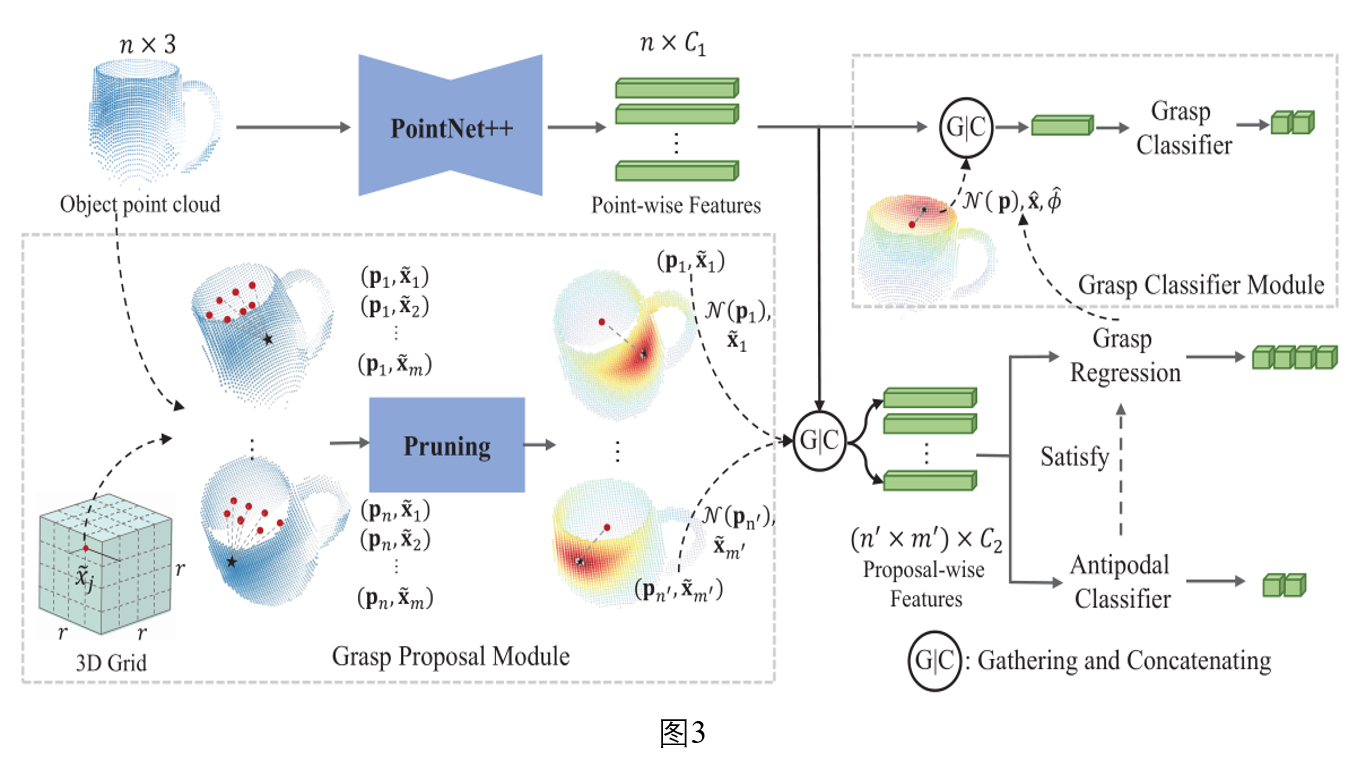
在抓取姿态估计任务中,我们的目标是从观测的图像或点云数据中,生成大量的精确的、多样的抓取姿态。因此,我们设计了以上的网络结构。我们提出的结构由五个模块组成,分别为:特征提取网络,抓取候选模块(Grasp proposal module),对跖检测模块(Antipodal classifier),抓取回归模块(Grasp regression),抓取分类模块(Grasp Classifier)。
在特征提取网络中,我们采用PointNet++[7]网络对输入的点云提取逐点的特征。
在抓取候选模块中,我们假设抓取姿态g的接触点落在观测的点云P上,即所观测点云的每一个点都可作为潜在的抓取接触点。同时,我们在世界坐标系中定义一个三维网格 ,把网格中的每一个顶点都作为抓取中心点的锚点。我们将观测点云上的点$\textbf{p}_i$与三维网格的顶点$\tilde{\textbf{x}}_j$组成一对$(\textbf{p}_i,\tilde{\textbf{x}}_j)$,这就是我们所说的抓取候选(grasp proposal)。由于这种方式会产生大量的抓取候选,我们采用以下方式对它们进行裁剪:1)把落在物体包围框外的三维网格顶点去除掉;2)我们保留那些离ground truth抓取距离很近抓取候选,并把它们作为训练Antipodal classifier的正样本,同时只采一部分离ground truth抓取距离比较远的抓取候选作为负样本。在这种裁剪方式下,在训练阶段可以去除86%的无效的抓取候选。为了对不同的抓取候选进行区分,我们还提出了一种依赖于锚点(anchor-dependent)的特征提取方式,数学表达式如下:
$$\mathcal{N}(\mathbf{p}_i, \widetilde{\mathbf{x}}_j) = \{ \mathbf{p}_{i'} \ \vert \ d(\mathbf{p}_{i'}, \mathbf{p}_i) \cdot (\vert\cos( \overrightarrow{\mathbf{p}_i\mathbf{p}_{i'}}, \overrightarrow{\widetilde{\mathbf{x}}_j\mathbf{p}_i}) \vert + 1 ) \leq \varepsilon \}$$
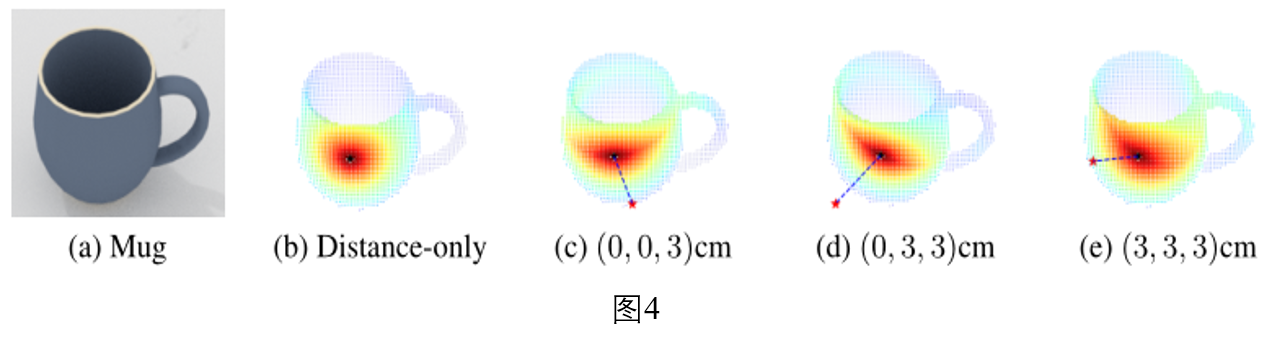
其中,$\mathcal{N}(\textbf{p}_i,\tilde{\textbf{x}}_j)$为$\textbf{p}_i$在输入点云$\textbf{P}$上的邻近点,其效果如下图所示,图(c-e)下为锚点坐标:
对跖检测模块(Antipodal classifier)是一个二分类网络,其目标是去除那些无效的抓取候选而保留那些与GT接近的抓取候选,此模块的损失函数如下:
$$\mathcal{L}_{AP}(\mathbf{p}_i, \widetilde{\mathbf{x}}_j) = - l_{AP}^{*}(\mathbf{p}_i, \widetilde{\mathbf{x}}_j)\log\hat{l}_{AP}(\mathbf{p}_i, \widetilde{\mathbf{x}}_j) - \left(1 - l_{AP}^{*}(\mathbf{p}_i, \widetilde{\mathbf{x}}_j)\right) \log\left(1 - \hat{l}_{AP}(\mathbf{p}_i, \widetilde{\mathbf{x}}_j)\right) .$$
由于抓取候选是比较粗糙的,锚点与抓取中心有一定的偏移,并且没有考虑爪子的俯仰角。因此,对于那些满足对跖检测的抓取候选,我们利用抓取回归模块(Grasp regression)进一步回归锚点与抓取中心点的偏移和俯仰角的余弦值。其损失函数如下:
$$\mathcal{L}_{REG}(\mathbf{p}_i, \widetilde{\mathbf{x}}_j) = \| \Delta_{\widetilde{\mathbf{x}}_j}^{*+} - \Delta_{\widetilde{\mathbf{x}}_j} \| + \frac{1}{K}\sum_{k=1}^K \omega_k |\cos\hat{\phi} - \cos\phi^{*+}_k| .$$
在[3]中,他们训练了一个独立的抓取评估网络对预测的抓取进行打分。在本文,我们提出了一个可以与Antipodal classifier和Grasp regression两个模块一起联合训练的抓取分类网络(Grasp classifier)。抓取分类网络是一个二分类网络,其目标是对预测的抓取姿态进行评分以挑选出成功率高的抓取姿态,其输入为接触点的邻近点$\mathcal{N}(\textbf{p})$的特征、抓取中心点$\textbf{x}$、抓取俯仰角$\textbf{ϕ}$。训练阶段,我们以3:7的比例采集抓取的正负样本,其损失函数如下:
$$\mathcal{L}_{CLS}(\hat{\mathbf{g}}) = - l_{CLS}^{*}(\hat{\mathbf{g}})\log\hat{l}_{CLS}(\hat{\mathbf{g}}) - \left(1 - l_{CLS}^{*}(\hat{\mathbf{g}})\right) \log\left(1 - \hat{l}_{CLS}(\hat{\mathbf{g}})\right) .$$
整个网络的损失函数如下:
$$\mathcal{L}_{GPNet} = \mathcal{L}_{AP} + \alpha\mathcal{L}_{CLS} + \beta\mathcal{L}_{REG}.$$
1. 数据集
由于[3]提出的数据集没有公开模拟器的环境配置,我们很难进行实验比较。因此,我们在ShapeNetSem[8]数据集上挑选了226个CAD模型,这些模型涵盖了8个类别(碗,瓶子,杯子,圆柱体,长方体,纸巾盒,苏打水盒,玩具车),其中196个模型用于训练,剩下30个用于测试。我们在模拟器环境中采集了22.6M个抓取标注(平均每个物体约100k个标注),其中23.6%为正样本,76.4%为负样本。同时,我们对每个物体,在1000个随机的角度下渲染了深度图,测试时采用的相机角度也是随机的。
2. 基于规则评价结果
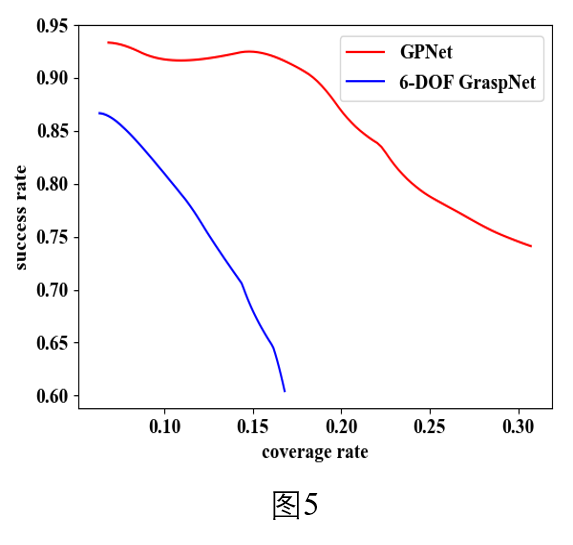
对于预测的抓取姿态$\textbf{g}=(\textbf{x},\textbf{θ})$,如果在标注的正样本抓取集合$G^+$中找到至少一个$\textbf{g}^+=(\textbf{x}^+,\textbf{θ}^+)$满足以下条件,我们则认为$\textbf{g}$是一个成功的抓取姿态,且$\textbf{g}^+$被$\textbf{g}$覆盖:(1) $\|\hat{\textbf{x}}-\textbf{x}^+\|_2 \leq25mm$, (2) $\|\hat{\textbf{θ}}-\textbf{θ}^+\|_2 \leq30^{\circ}$。我们可以得到如图5所示的 成功率-覆盖率 曲线,覆盖率越高表明生成的抓取多样性越好。我们可以看到,我们的方法GPNet比在成功率和预测多样性两个指标上,都比6-DOF GraspNet[3]好很多。注:此结果是将预测抓取姿态,经过非极大值抑制(NMS)算法筛选后的结果。
3. 模拟器测试结果
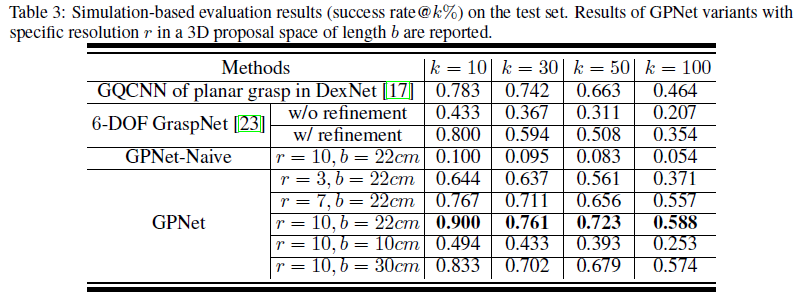
我们用训练好的模型对测试集的物体生成抓取姿态后,经过NMS算法筛选,放到模拟器里进行模拟抓取测试,其结果如下表所示,其中,success rate@k%指的是将预测的抓取姿态根据评分从高到低排序,前k%的成功率。r表示3D网格的分辨率,b表示3D网格的范围。可以看到我们的算法在模拟器抓取成功率上,比6-DOF GraspNet[3]和平面抓取算法GQCNN[6]都要好。
4. 真实环境测试
我们的真实环境测试配置如下图6所示,(a)为测试的物体,(b)为测试的硬件设备:

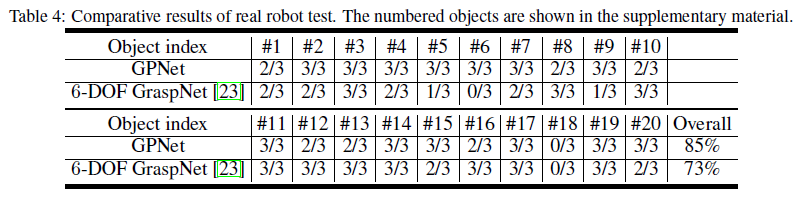
我们比较了GPNet和6-DOF GraspNet[3]两种算法,结果如下表。 可见,GPNet比6-DOF GraspNet[3]在真实环境的测试结果要好。
本文提出了一个可以生成精确、多样的六自由度抓取的网络结构GPNet。GPNet的特点在于利用锚点的方式生成抓取候选,并用Antipodal classifier对抓取候选进行筛选,进一步用Grasp regression模块回归更加精确的抓取姿态,最后用Grasp classifier对生成的抓取进行评分。整个网络可以进行端到端训练。为验证我们提出的方案,我们还提出了一个六自由度的抓取数据集。实验证明,GPNet在抓取成功率和生成多样性上,都比现有的四自由度或六自由度抓取方案要好。GPNet具有一定的实用性。
参考文献
[1] A. Depierre, E. Dellandrea, and L. Chen, “Jacquard: A Large Scale Dataset for Robotic Grasp Detection,” IEEE Int. Conf. Intell. Robot. Syst., pp. 3511–3516, 2018.[2] L. Pinto and A. Gupta, “Supersizing self-supervision: Learning to grasp from 50K tries and 700 robot hours,” Proc. - IEEE Int. Conf. Robot. Autom., vol. 2016-June, pp. 3406–3413, 2016.
[3] A. Mousavian, C. Eppner, and D. Fox, “6-DOF GraspNet: Variational Grasp Generation for Object Manipulation,” May 2019.
[4] M. Gualtieri, A. Ten Pas, K. Saenko, and R. Platt, “High precision grasp pose detection in dense clutter,” IEEE Int. Conf. Intell. Robot. Syst., vol. 2016-Novem, pp. 598–605, 2016.
[5] F.-J. Chu, R. Xu, and P. A. Vela, “Real-world Multi-object, Multi-grasp Detection,” vol. 3766, no. 1, pp. 1–8, 2018.
[6] J. Mahler et al., “Dex-Net 2 . 0 : Deep Learning to Plan Robust Grasps with Synthetic Point Clouds and Analytic Grasp Metrics.”
[7] C. R. Qi, L. Yi, H. Su, and L. J. Guibas, “PointNet++: Deep hierarchical feature learning on point sets in a metric space,” Adv. Neural Inf. Process. Syst., vol. 2017-December, pp. 5100–5109, 2017.
[8] A. X. Chang et al., “ShapeNet: An Information-Rich 3D Model Repository,” 2015.